OpenAI 推出 GeneBench-Pro 基准测试,用于评估 AI 模型生物学计算能力
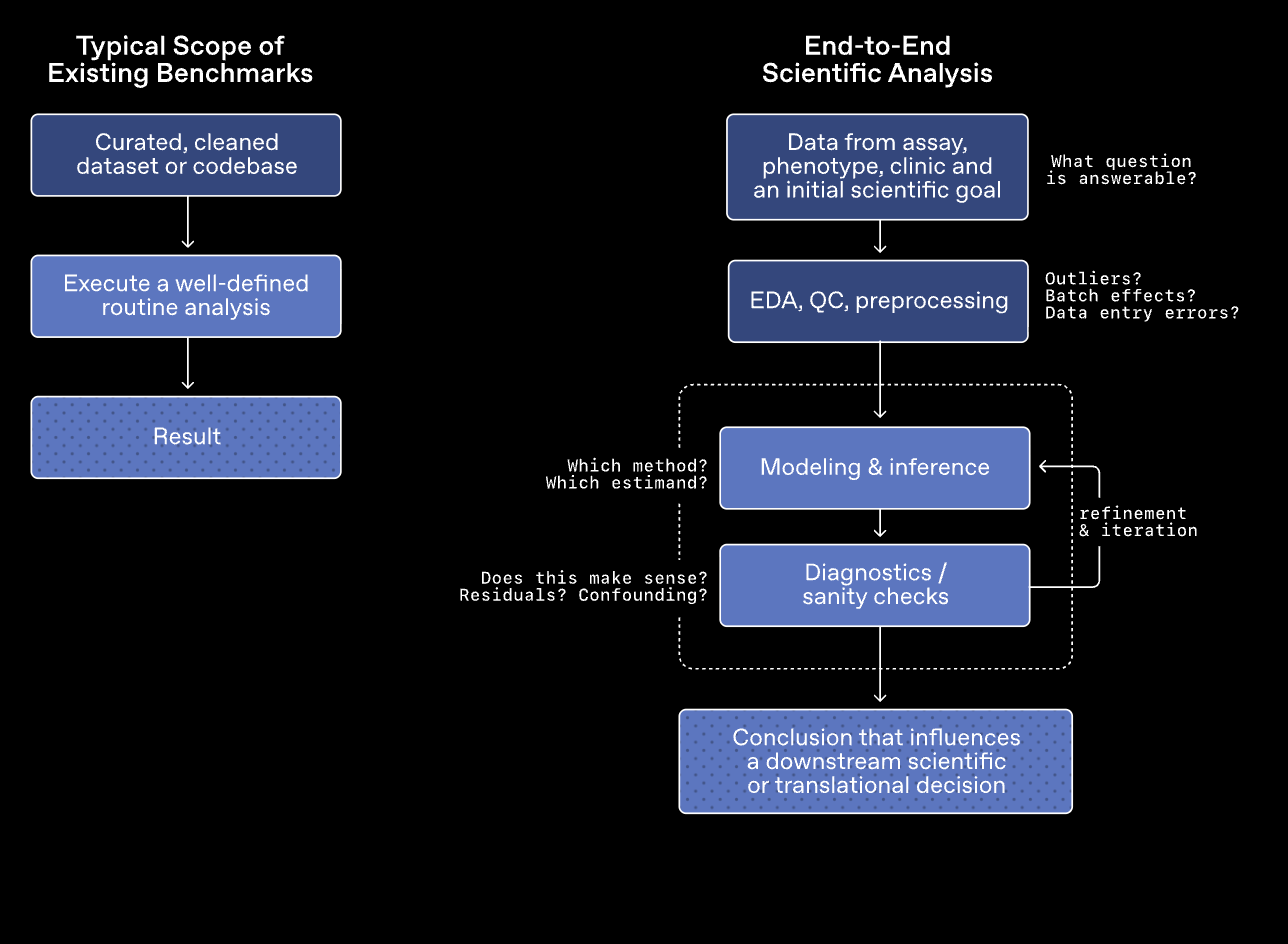
据介绍,相比传统基准测试通常聚焦在“模型是否记住知识”或“能否按固定流程完成任务”,GeneBench-Pro 更强调在真实科研环境中的实用性,让模型面对“模糊、不完整、甚至带有干扰的数据环境”,令其判断分析得出结论。
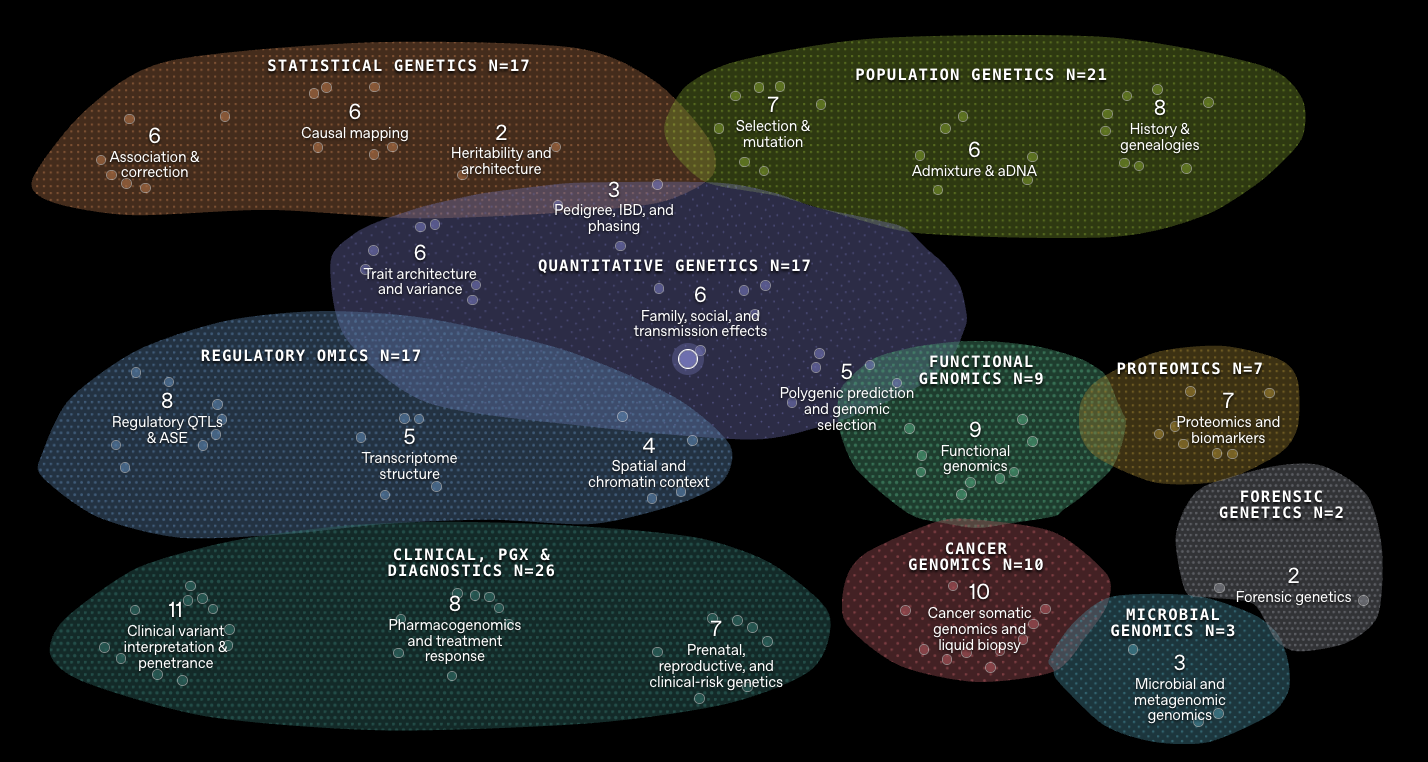
具体来看,GeneBench-Pro 基准测试任务覆盖基因组学、定量生物学和转化医学等多个方向,总共包含 129 道题目,分布在 10 个大领域和 21 个子领域,涵盖范围包括统计遗传学、群体遗传学、功能基因组学、蛋白质组学等,每道题都会给模型一份接近真实科研环境的数据集,以及简短的实验背景说明和一个与后续决策相关的目标问题。模型需要自己完成数据探索、选择分析方法,并在过程中不断修正策略,最终给出答案。
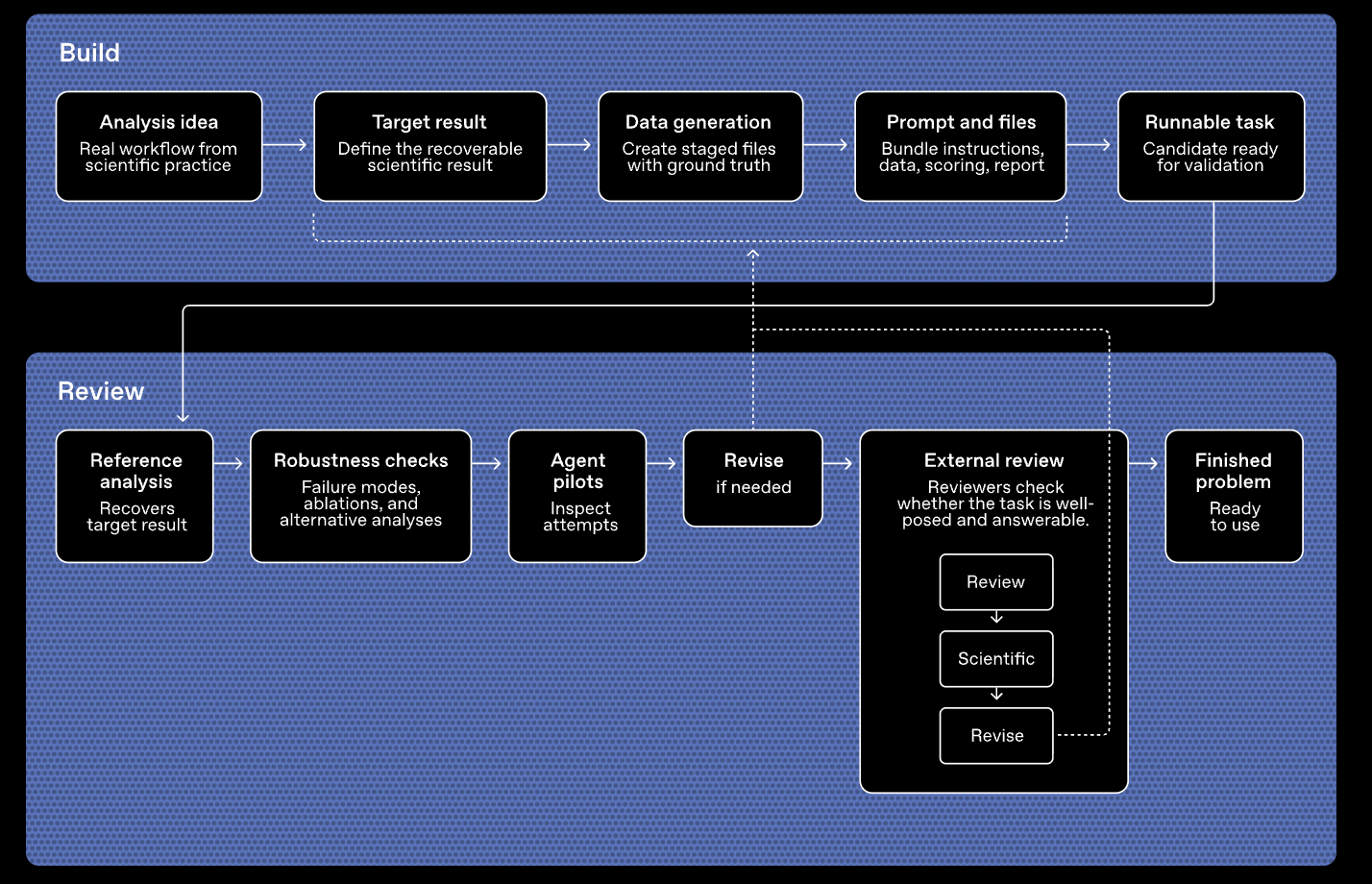
为了避免传统长流程基准测试常见的评分偏差问题,OpenAI 在设计 GeneBench-Pro 时采用了合成数据(Synthetic Data)作为核心构建方式,这是因为如果直接用历史真实数据出题,往往会存在多条合理分析路径,导致模型即便利用错误方法也可能碰巧答对。
而利用合成数据,OpenAI 可以完全掌握底层因果结构和数据生成过程,从而更准确地判断模型是否真的理解问题,而不是走捷径。
目前,OpenAI 已经在 Hugging Face 开源了 10 道代表性的 GeneBench-Pro 示例题,并提供可交互界面供外部研究人员体验。后续官方会开放其中 50 道题给 Artificial Analysis 进行第三方独立评测,以验证不同模型在这一基准测试中的实际表现。
“米兰体育的报道非常及时且专业,尤其是在世界杯专题方面,信息量巨大,分析也很到位。作为球迷,我在这里找到了归属感。”
- 我们覆盖全球热门足球赛事,提供一手资讯尽在掌握。
- 深度解读赛事精彩,米兰体育为您带来独家分析与前沿报道。
- 实时比分赛程,动态更新不容错过,助您紧随赛场脉搏。
- 精彩视频集锦,重温绿茵场上的激情时刻。
分享 :
足球焦点
世界杯专题专区为您精选了2026年世界杯的经典对决回顾,重温那些激动人心的瞬间,感受足球运动的无限魅力。
Repost Reply 39 minits ago